
How to Identify Vulnerabilities in code – Manual Code Review
How to Identify Vulnerabilities in code – Manual Code Review
No matter how much care you take during development of any software, security issues creep in. Hence, it is important to get the code reviewed for security loopholes. Code is the only advantage for organizations over the hackers and they need to utilise this fact in a planned way. Relying only on penetration testing is definitely not a good idea. When you have the code, use the code! So How to Identify Vulnerabilities in code ? Let’s learn!
Most organisations today rely on commercial tools such as IBM Appscan, HP Fortify etc. for code reviews. These tools scan the entire code and locate potential issues by looking for use of certain APIs and functions within the code. The security reviewer then needs to manually verify these issues and confirm the findings. This approach definitely saves time if you can afford the license cost. It also involves the risk of not identifying all the potential issues (as is the case with any tool). Without the help of a tool, the reviewer has to understand pages/locations of interest and verify the code. In any case, reviewing the code and identifying the issue has to be done manually. In this article, we will focus on how a security professional can identify some of the most common vulnerabilities within an application. Below are the common steps involved while performing a code review at a high level:
Identify the objectives of review:
Reviews are much effective with objectives in place. Below are some of the questions that help you to understand the objectives of your review:
- What is the scope of the review?
- What are the technologies used in the application?
- What are the vulnerabilities against which the code will be reviewed?
Identifying areas / components of interest:
Identifying important components needs to be done with the help of development team. For example, identifying components that handle authorization, sessions etc. can be done at this stage. Having a proper understanding about what the application is about and what it handles would definitely help the reviewer to connect certain dots while performing the review. Consult the development team to know about applications functionality, features, and architecture and so on. Learn More about how to identify entry points in detail (click here).
Reviewing the code:
Perhaps this is the most important and heavily weighted part compared to the other steps. Automated source code scanners are commonly used for code analysis. They scan the code and present the reviewer with thousands of identified findings that may be valid or false positives. It is now up to reviewer to figure it out by actually reviewing that piece of code. The point is that in spite of using automated tools, it is still essential to perform manual review. For remaining part of the article, we will discuss in detail about how code can be reviewed to identify potential issues.
Reviewing the code for a particular vulnerability boils down to looking for key pointers related to that vulnerability within the code. It entirely depends upon what vulnerability you are looking for. For instance, the approach that is used for reviewing XSS would be very much different from the one used for SQLi. Although it would be desirable to manually review every line of code comprehensively, it is not possible in real world especially with large applications. Hence, it is important to have a perspective about what to find in the code – What am I looking for in this piece of code?
There are two types of techniques to run through the code during code analysis:
- Control flow analysis
- Data flow analysis
Control Flow Analysis: As part of control flow analysis the reviewer sees through the logical conditions in the code. The reviewer looks at a function and identifies various branch conditions such as loops, if statements, try/catch blocks etc. He will then figure out under what circumstances each branch is executed. While performing the control flow analysis, below are some of the questions (these are only a sample) that a reviewer needs to consider.
- Does the application rely on client side validation?
- Does the application embed sensitive information (such as passwords) in the code?
- Is sensitive data being stored in predictable locations (such as temp files), or being sent in clear text over the network?
- Is there proper and consistent error checking?
- Do error messages give away too much information?
- Does the application expose sensitive information via user session?
Data Flow Analysis:
Dataflow analysis is the mechanism used to trace data from the points of input to the points of output. This will help you find bugs associated with poor input handling. This is the technique commonly used to identify several issues such as cross-site scripting, SQL injection etc. Below are the steps involved in this process:
- Identify the source of input. Determine whether it is trusted or untrusted. Any data coming from the user is considered to be untrusted input.
- Trace the flow of data to each possible output. Look for any data validation snippets involved in this path.
- Identify where the data finally ends up.
While doing the data flow analysis, although the approach remains same, the analysis depends on underlying vulnerability. For example, let us consider the case of cross-site scripting to see how data flow analysis is done. In the case of XSS, we mainly look for certain APIs that interface with the external world. To explain in simple terms, cross-site scripting involves two things – Accepting input from user and displaying it back. Hence, there are two steps that we need to do while reviewing the code for XSS:
Step 1: Identify ‘source’: Look for those API’s that are used to accept data from external sources. Identifying the potential sources is done by looking for various API’s that are used to accept the data. For example below are the key areas to look for when dealing with ASP.NET:
Accepting User Input [Commonly used]:
request.form
request.querystring
request.url
request.httpmethod
request.headers
request.cookies
TextBox.Text
HiddenField.Value
Accepting User Input [Others]:
InputStream
request.accepttypes
request.browser
request.files
request.item
request.certificate
request.rawurl
request.servervariables
request.urlreferrer
request.useragent
request.userlanguages
request.IsSecureConnection
request.TotalBytes
request.BinaryRead
recordSet
Step 2: Trace the flow: The above functions can be the ‘source’ of unvalidated data. Here we need to figure out if the application is performing input validation on the data before processing it. If blacklisting is done for certain values like script etc. then there is always a chance to bypass them.
Step 3: Identify the ‘sink’: Once we identify the source, we then need to understand what the application is doing with this data. Problems would arise if the application directly displays this to the user (reflected xss), or if it stores this in database and displays it at a later point of time (stored xss). Hence, the next step is to identify those functions that are used for sending responses to the client. For example below are the functions that are commonly used in ASP.NET to send responses to the client. These are called ‘sinks’.
Sending Response [Commonly used]:
response.write
<% =
Lable.Text
HttpUtility
HtmlEncode
UrlEncode
innerText
innerHTML
If the application output encodes the data (for example with the use of functions such as HtmlEncode), then it is considered to be safe. Automated scanners do this job of identifying sources and sinks effectively and offer a clear view as shown in the below figure:
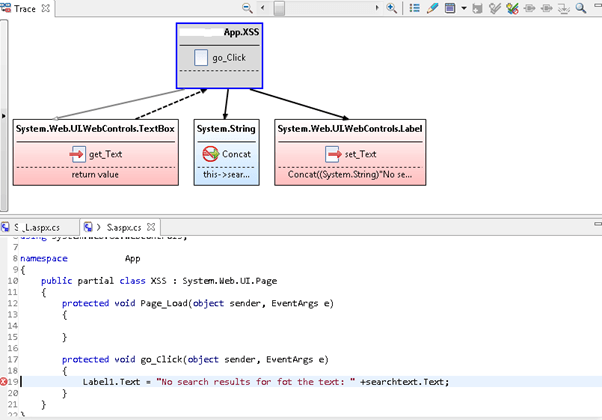
Thus depending on the underlying vulnerability code needs to be analysed in a systematic way to confirm the existence of the issue.
Broken Authentication and Session Management Vulnerability is one the Top 10 Owasp vulnerabilities. Broken authentication and Session Management this year jumps to #2 in the list. Normally developers doesn’t concentrate much on How users session is being managed. This negligence results into inducing Broken Authentication and Session Management vulnerabilities in the web applications which is quite a bit hard for developers to detect by themselves.

User authentication on the web typically involves the use of a userid and password. Stronger methods of authentication are commercially available such as software and hardware based cryptographic tokens or biometrics, but such mechanisms are not present on most web applications. Web-based applications frequently use sessions to provide a friendly environment to their users. HTTP is a stateless protocol, which means that it provides no integrated way for a web server to maintain states throughout user’s subsequent requests. In order to overcome this problem, web servers – or sometimes web applications – implement various kinds of session management. The basic idea behind web session management is that the server generates a session ID at some early point in user interaction, sends this session ID to the user’s browser and makes sure that this same session ID will be sent back by the browser along with each subsequent request. Session IDs thereby become identification tokens for users, and servers can use them to maintain session data (e.g., variables) and create a session-like experience to the users.
There are three widely used methods for maintaining sessions in web environment: URL Parameters, Hidden form fields and cookies. Each of them has its own benefits and shortcomings, cookies have proven to be the most convenient and also the least insecure of the three. From security perspective, most known attacks against cookie-based session maintenance schemes can also be used against URL parameters or hidden form fields, while the reverse is not true. This makes cookies the best choice security-wise.
Very often, session IDs are not only identification tokens, but also authenticators. This means that upon login, users are authenticated based on their credentials (e.g., usernames/passwords or digital certificates) and issued session IDs that will effectively serve as temporary static passwords for accessing their sessions. This makes session IDs a very appealing target for hackers. In many cases, an hacker who manages to obtain a valid Session ID of user’s session can use it to directly enter that session – often without arising user’s suspicion. Interestingly, most cross-site scripting exploits focus on obtaining the session ID stored in browser’s cookie storage. This class of attacks, where the attacker gains access to the user’s session by obtaining his session ID, is called session hijacking.
Broken Authentication and Session Management Attacks which are quite common among hackers are listed below:
1. Brute Force Attacks
2. Session Spotting Attacks
3. Replay Attack
4. Session Fixation Attack
5. Session Hijacking
6. Session Expiration Attack
We will discuss these attacks in our later tutorials one by one and methods to prevent these attacks. So keep connected and Keep Learning.
In our previous tutorials we have learned about two types of cross site scripting i.e. Reflected Cross Site Scripting and Stored Cross Site Scripting. Most of our readers must be interested in do we have some XSS attack which is mixture of both. Yes, we have DOM based XSS. DOM Based XSS is an mixture of Reflected XSS and Stored XSS. In a DOM-based XSS attack, the malicious script is not actually parsed by the victim’s browser until the website’s legitimate JavaScript is executed. But before that we must understand what is DOM?
Wikipedia states that “The Document Object Model (DOM) is basically a cross-platform and language-independent convention for representing and interacting with objects in HTML, XHTML, and XML documents. The nodes of every document are organized in a tree structure, called the DOM tree. Objects in the DOM tree may be addressed and manipulated by using methods on the objects. The public interface of a DOM is specified in its application programming interface (API). ”
To render a document such as an HTML page, most web browsers use an internal model similar to the DOM. The nodes of every document are organized in a tree structure, called the DOM tree, with topmost node named “Document object”. When an HTML page is rendered in browsers, the browser downloads the HTML into local memory and automatically parses it to display the page on screen. The DOM is also the way JavaScript transmits the state of the browser in HTML pages.
DOM BASED XSS ATTACK
DOM Based XSS is an XSS attack wherein the attack payload is executed as a result of modifying the DOM “environment” in the victim’s browser used by the original client side script, so that the client side code runs in an “unexpected” manner. That is, the page itself (the HTTP response that is) does not change, but the client side code contained in the page executes differently due to the malicious modifications that have occurred in the DOM environment.
In DOM-based XSS attack, there is no malicious script inserted as part of the page; the only script that is automatically executed during page load is a legitimate part of the page. The problem is that this legitimate script directly makes use of user input in order to add HTML to the page. Because the malicious string is inserted into the page using innerHTML, it is parsed as HTML, causing the malicious script to be executed.
Lets understand DOM based XSS attack with help of an example:
Suppose a developer made a website and he want’s to provide content in multiple languages i.e. he wants that his users can select language of their choice. But as per requirement, website mush have some default language too. This functionality can be invoked using below URL:
http://www.abcdefg.com/page.html?default=English
DOM based XSS can be achieved if hacker is able to insert his/her code in default tag and attack string will look something like below:
SCRIPT>></script>
When the victim clicks on this link, the browser sends a request for:
/page.html?default=<script><<MALICIOUS SCRIPT>></script>
to www.abcdefg.com. The server responds with the page containing the above Javascript code. The browser creates a DOM object for the page, in which the document.location object contains the string:
SCRIPT>></script>
The original Javascript code in the page does not expect the default parameter to contain HTML markup, and as such it simply echoes it into the page (DOM) at runtime. The browser then renders the resulting page and executes the attacker’s script:
<<MALICIOUS SCRIPT>>
Note that the HTTP response sent from the server does not contain the attacker’s payload. This payload manifests itself at the client-side script at runtime, when a flawed script accesses the DOM variable document.location and assumes it is not malicious.
Note : In the example above, while the payload was not embedded by the server in the HTTP response, it still arrived at the server as part of an HTTP request, and thus the attack could be detected at the server side.
That’s all for today! Enjoy guys and have happy learning.
In our previous tutorial of Stored Cross Site Scripting, we learned what Stored XSS was and how it works. Today we will learn more abou tStored XSS and how to find a website is vulnerable to a Stored XSS attack. Let’s have a basic preview of how Stored XSS works, a recap of what we learned in our previous tutorial. Below are the basic steps involved:
- Identify data entry points from where data is keyed into database.
- Analyze the HTML code of input web forms for potential vulnerability.
- Verify that input web form is vulnerable to Stored XSS.
The above process is somewhat similar to what we learned in the Reflected XSS Tutorial. Let’s learn each of the above points in detail to understand the Stored XSS attack.
Identification of Data Entry Points
The very first step is to identify all the data entry points from where a user can key data into a database i.e. from where all pages data is updated into database. Typical examples of stored user input can be located in:
- File Manager: Application that allows users to upload files, for example avatars, images, documents etc.
- Settings or Preferences: Pages that allow users to set preferences.
- Forums: application that allows exchange of posts.
- Comments on Blogs: blogs allowing users to submit comments
- Shopping Carts: application that allows users to store items into cart which they can view later.
- User profiles: Where user enters his/her info so that others can view it.
- Logs: application that maintains user inputs in form of logs.
Every application which accepts data as input from the user and stores it somewhere in its database is a potential entry point into the system.
Analyze the HTML Code for Tracing Vulnerability
Most website or web applications use HTML tags and Javascript for storing input from the user. Finding vulnerability is one thing but understanding the base line is another. So let’s first learn how input is stored in a web page or application.
Consider an example of normal login form of any portal which has login functionality say xyz.com; its logging snippet will look something like below if you inspect the HTML code.
<input id=”Email” name=”Email” placeholder=”Email” value=”abc@email.com” spellcheck=”false” class=”” ENGINE=”email”>
We are interested in the value of “value” tag. In the above case, the hacker has to identify a way to inject the arbitrary code outside the input tag as shown below:
<input id=”Email” name=”Email” placeholder=”Email” value=”abc@email.com” spellcheck=”false” class=”” ENGINE=”email”>Arbitrary Malicious Code Snippet <!– />
Verify Input Web Form for Stored XSS Vulnerability
This step involves verification of input validations and filtering criteria of web application. Suppose we inject the below code in above login snippet:
<script>alert(document.cookie)</script> or %3Cscript%3Ealert(document.cookie)%3C%2Fscript%3E
Then above login snippet will become something like below:
<input id=”Email” name=”Email” placeholder=”Email” value=”abc@email.com” spellcheck=”false” class=”” ENGINE=”email”><script>alert(document.cookie)</script>
Now if the input from the user is not correctly validated by the web owner then the above code will result into a popup containing cookie values. If you get a pop up with cookie values then it means the website is vulnerable to stored XSS and now you can inject whatever you wish (browser executable script).
Now every user will get this popup when he/she will reload the infected website or web page.
Stored XSS can be exploited by advanced JavaScript exploitation frameworks like XSS Proxy, BeEF, Backframe etc.
That’s all for today! In our next tutorial we will learn how to use BeEF framework to exploit Stored XSS in any webpage, so stay connected.
About Gamemaker gafoor.2





No comments